
Skills:
Physical Computing
Python (NLP)
Mechanical Design (CAD)
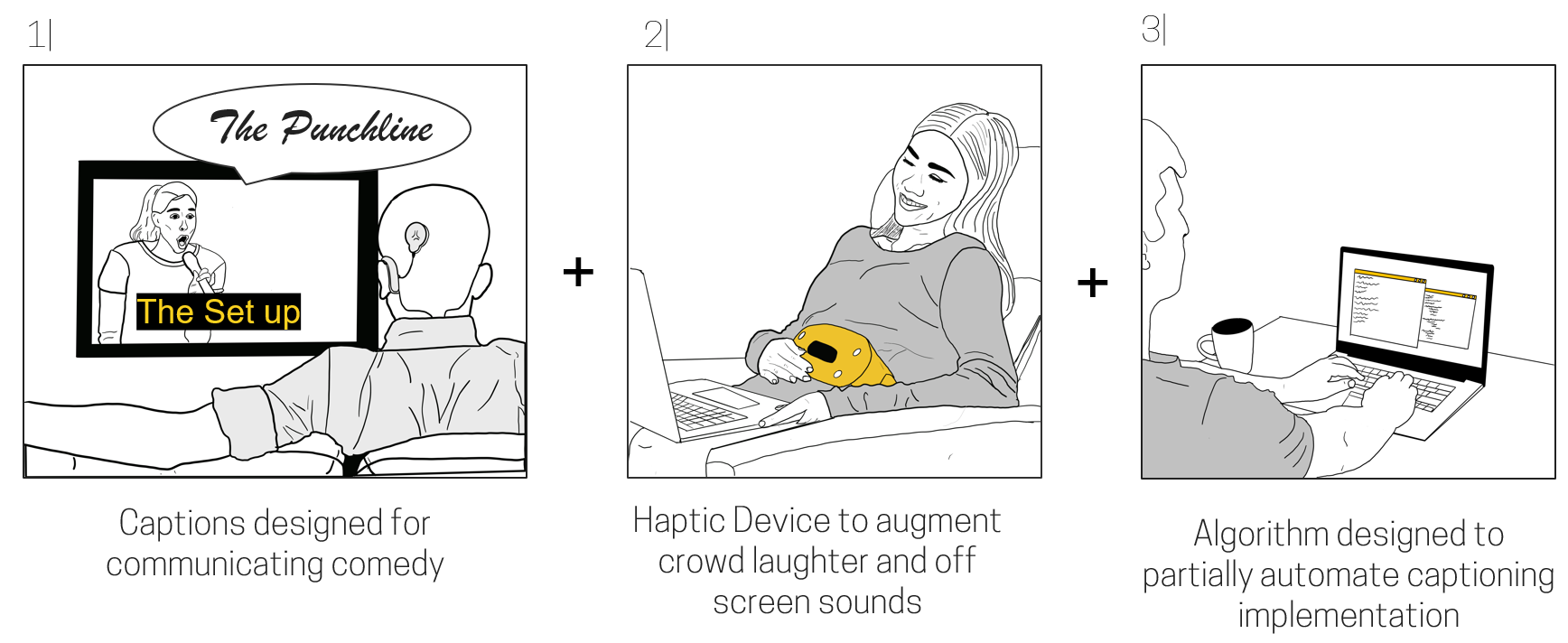
Captic; Providing accessible and expressive humor for hard of hearing viewers through captions and haptics.
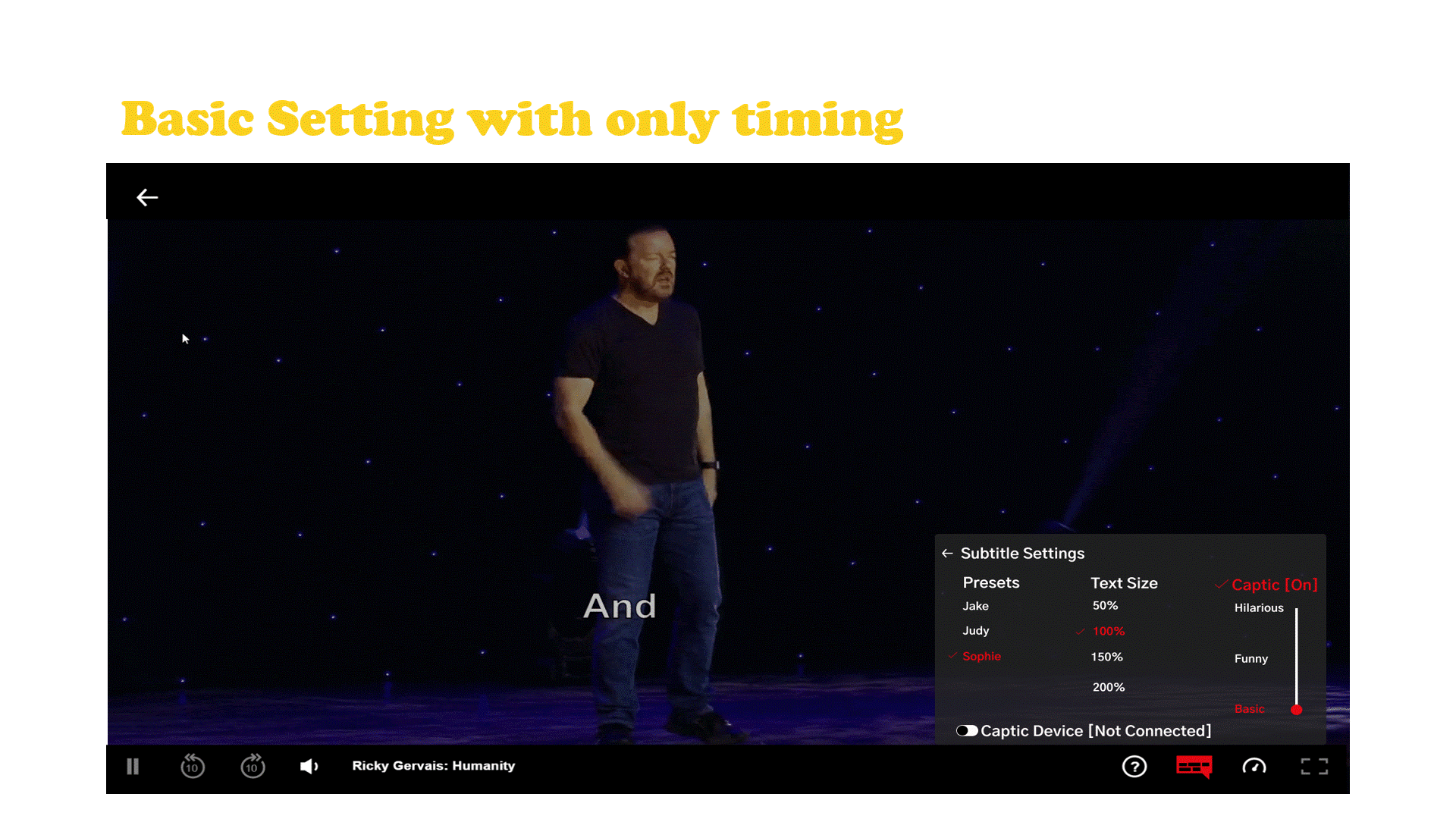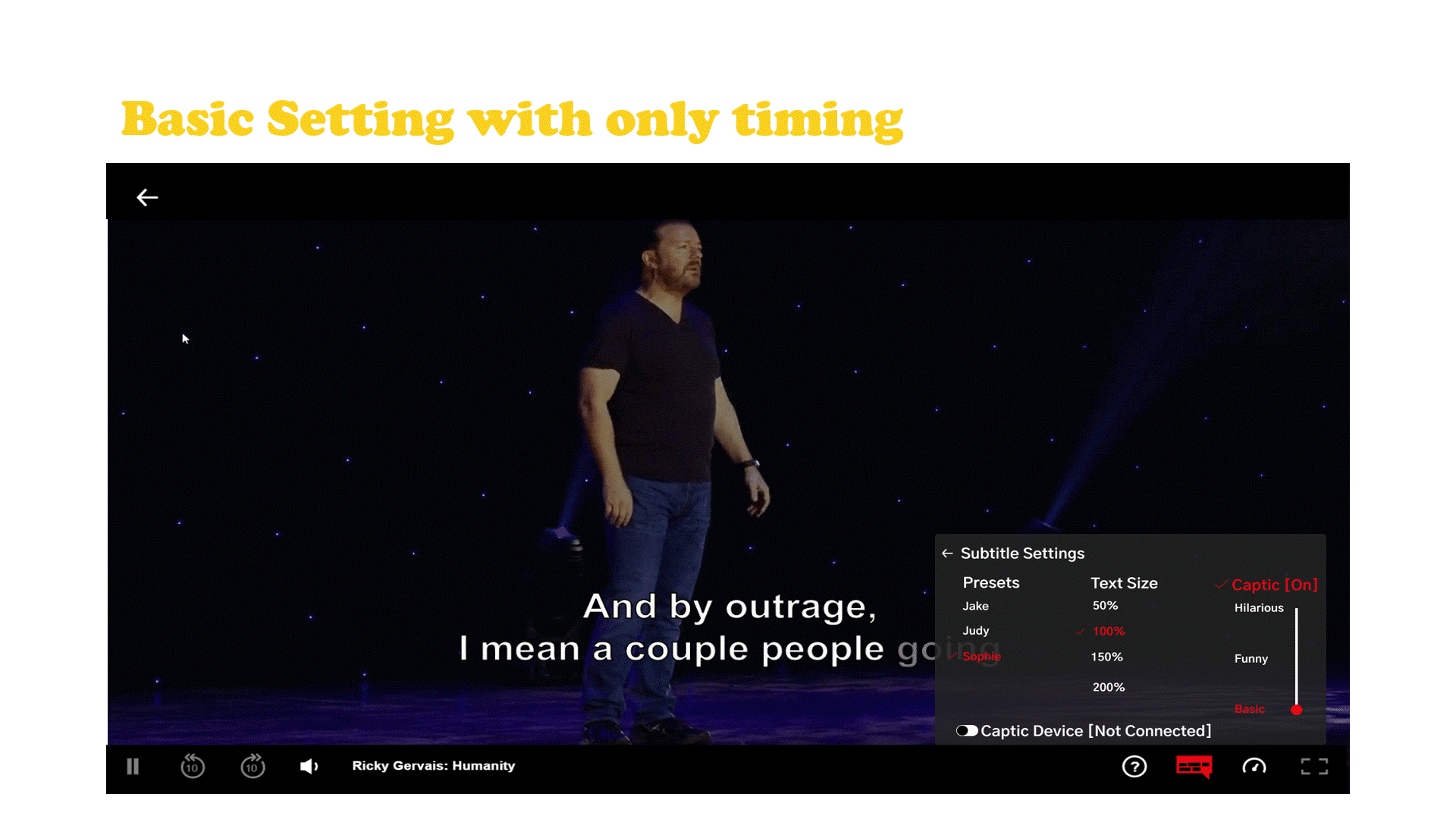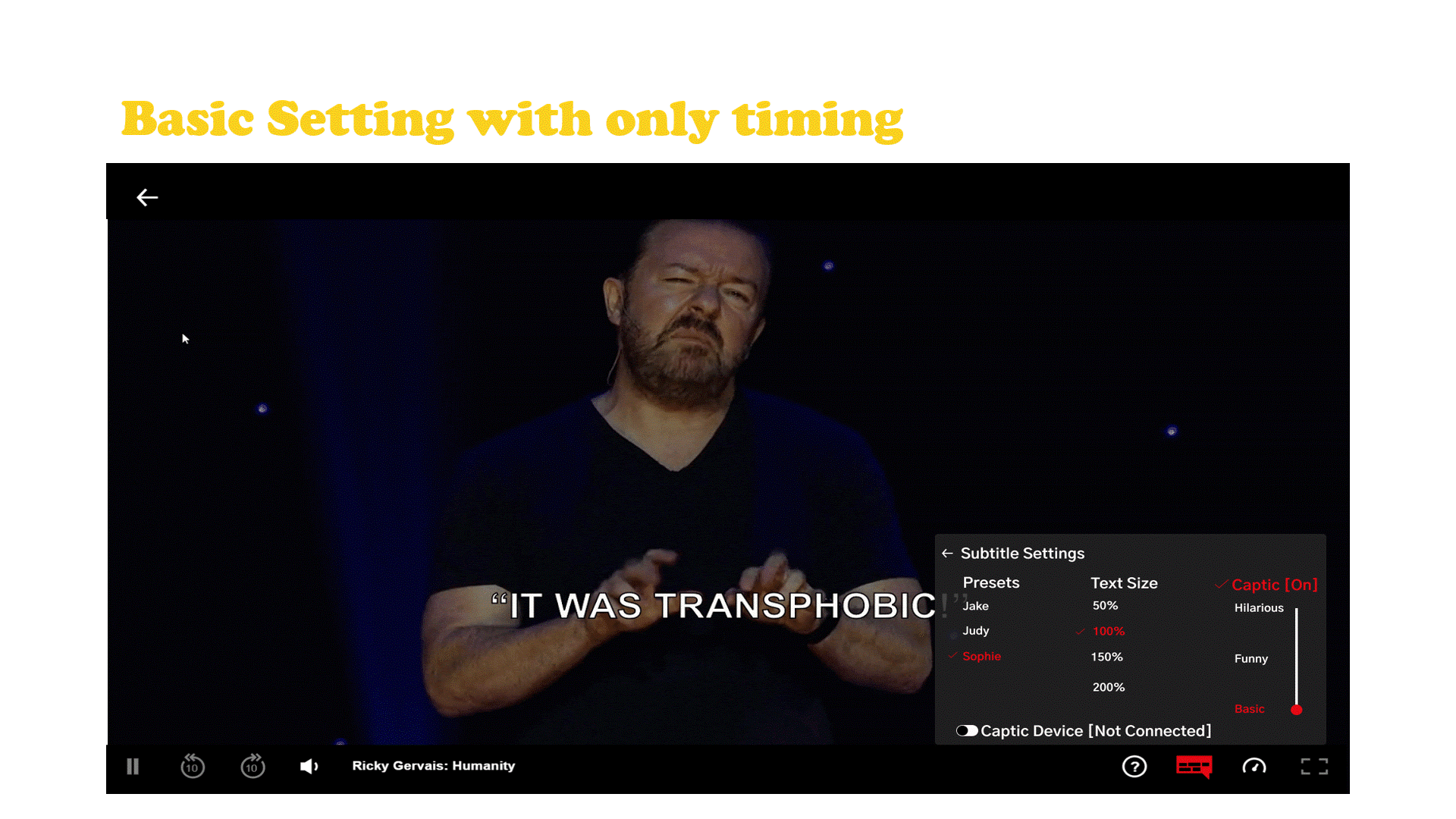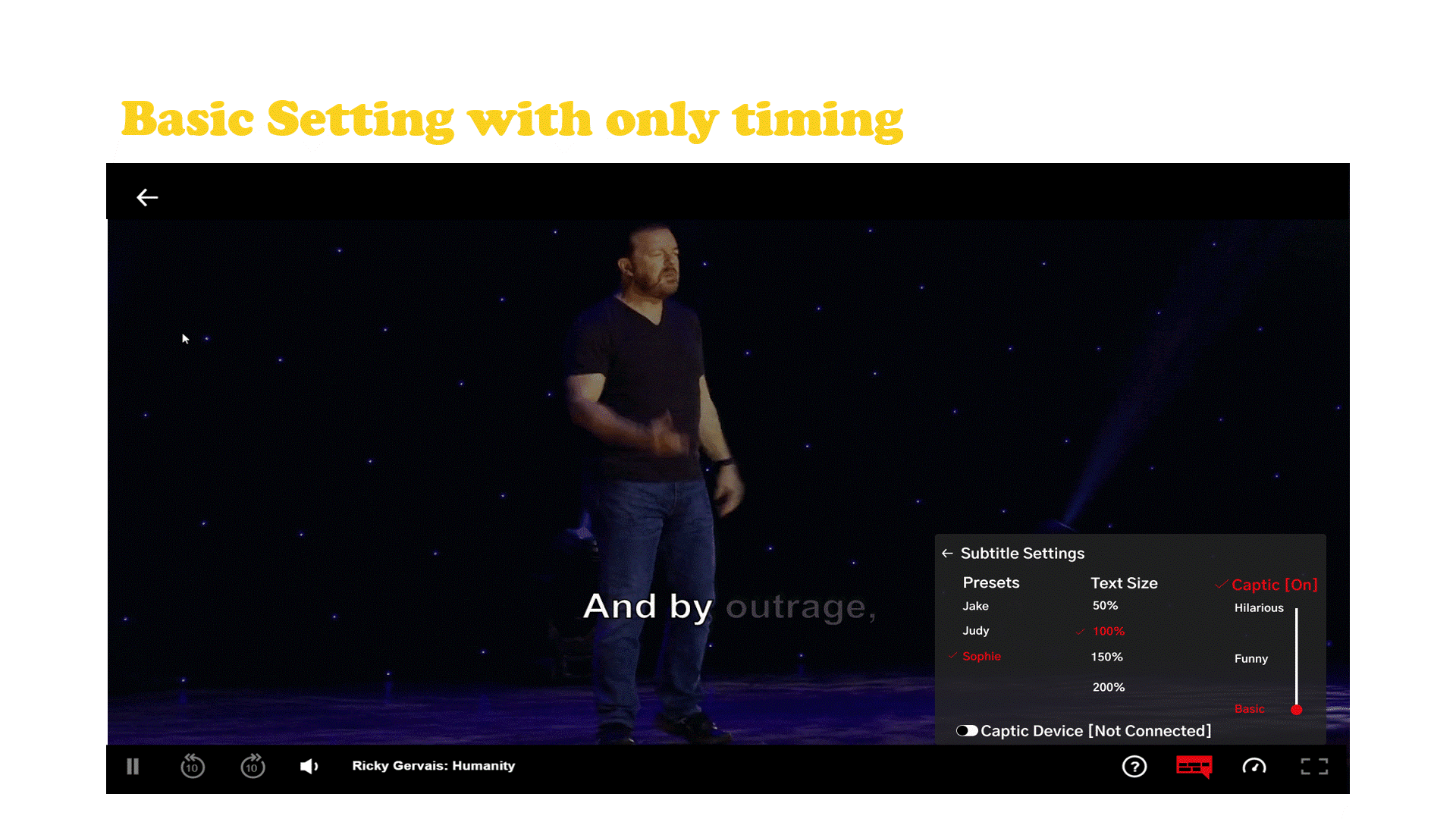
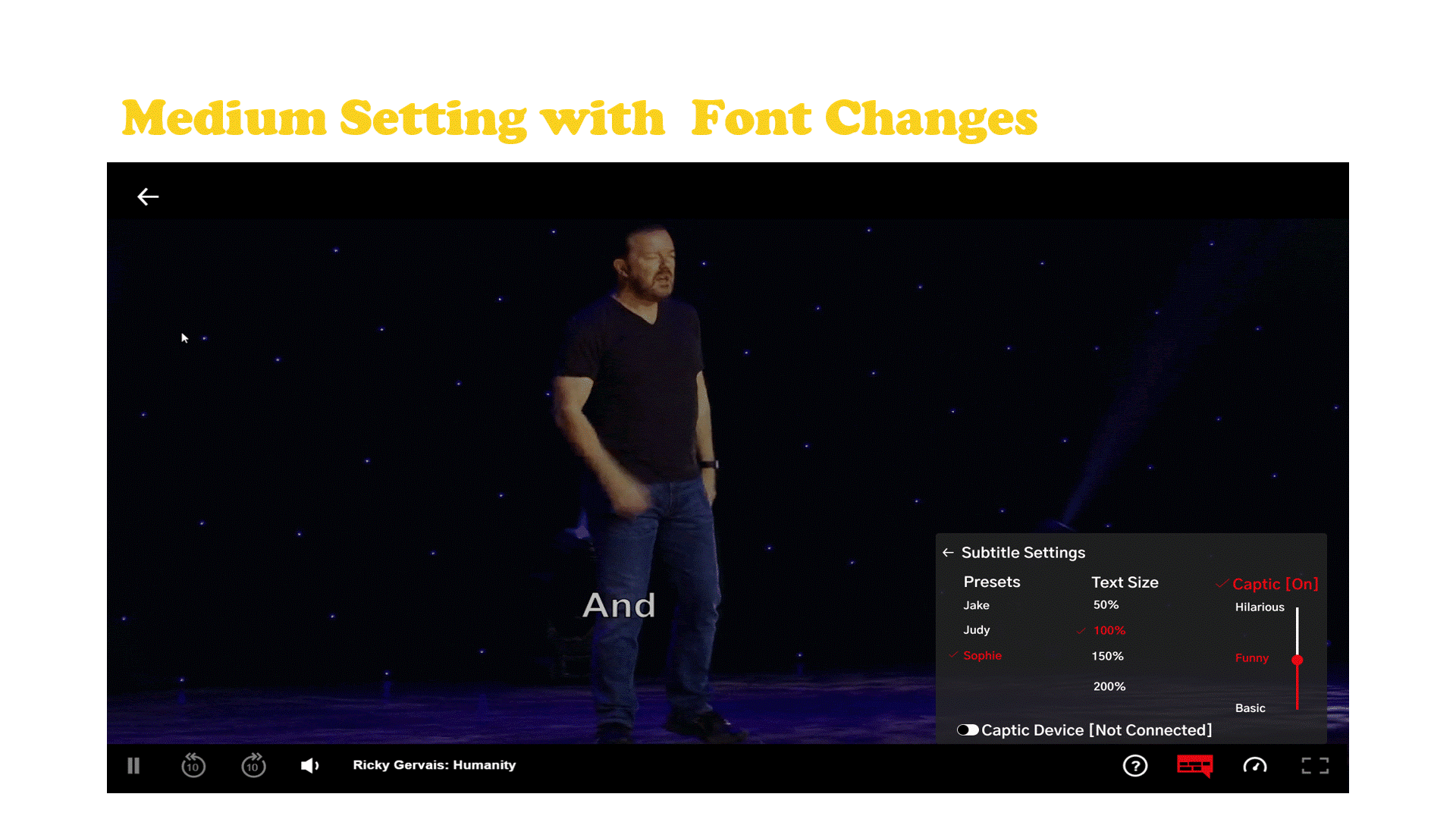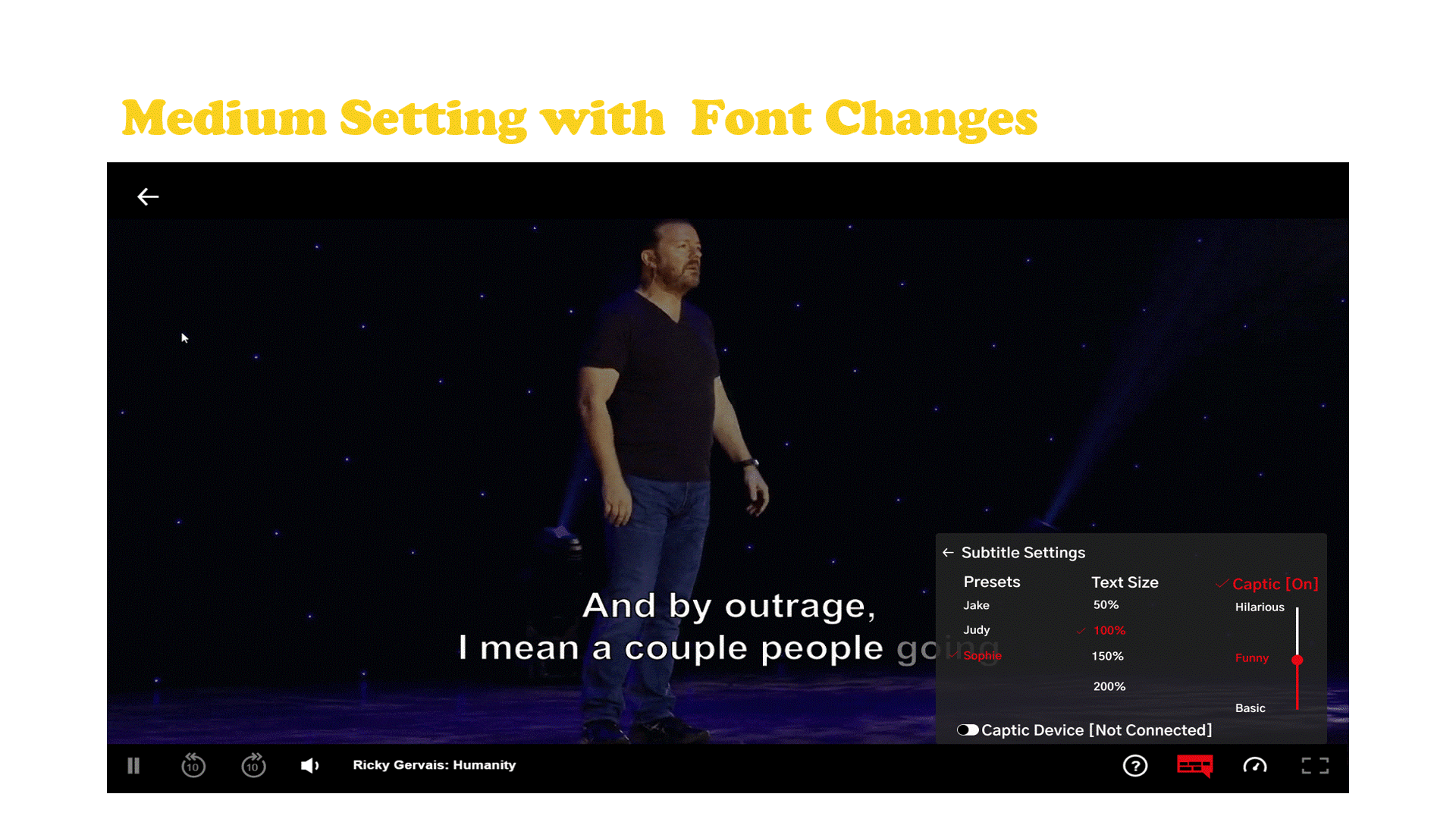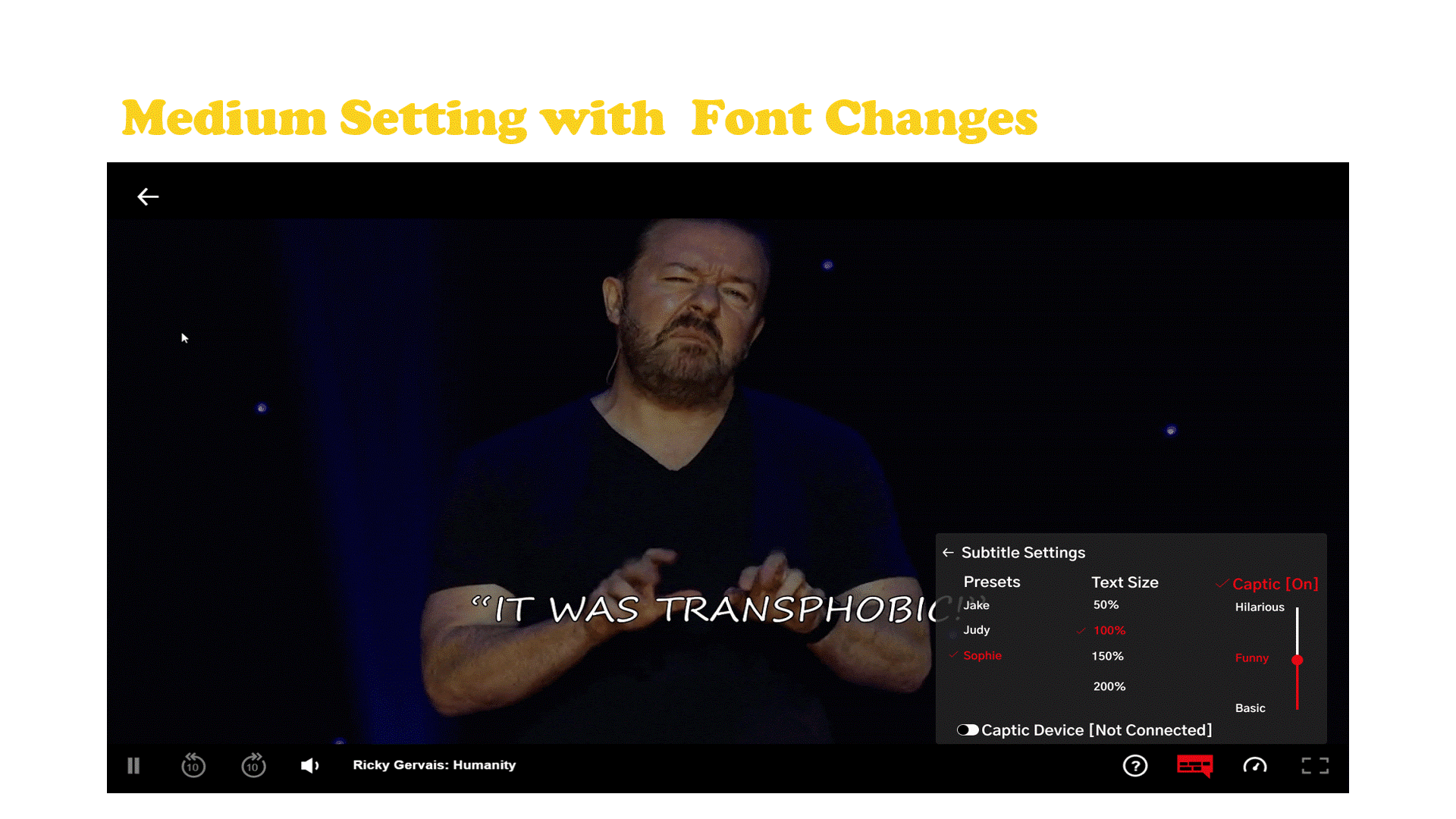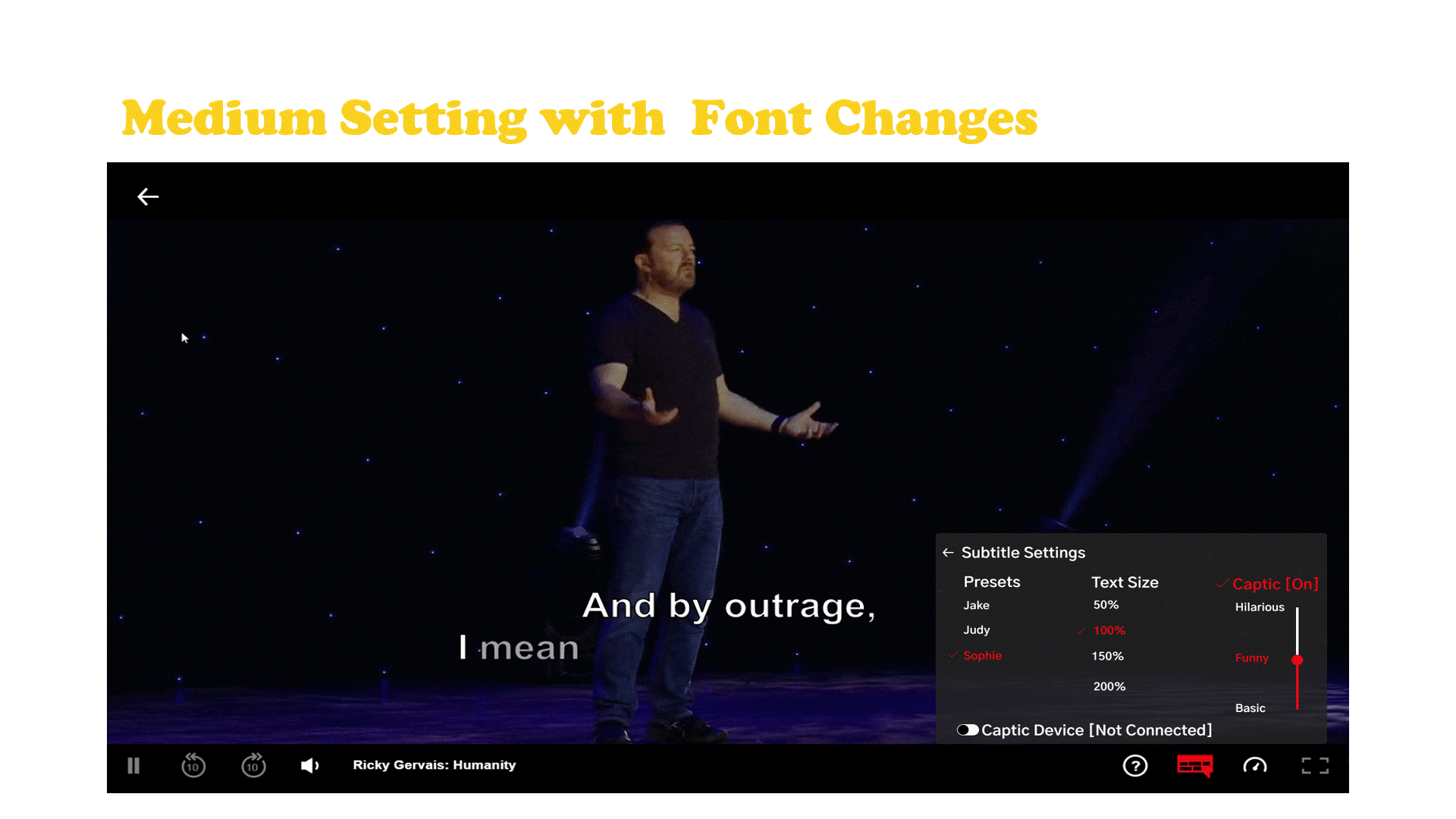
Captic is a system that communicates how a joke is verbally spoken to a hard of hearing individual through thoughtfully designed captions and an immersive haptic experience. The captions are enhanced by leveraging typographical elements and added text animations to give words more life, emotion, and meaning. Captic helps viewers feel the audience’s laughter and off screen sounds through vibrations, substituting one’s sense of hearing with the sense of touch.
The Captic captioning system is powered by artificial intelligence designed to partially automate the implementation of this new style of captions by a post processing department. Along with the captions there is a wearable that is part of a small hardware ecosystem.
What is Captic?
Context
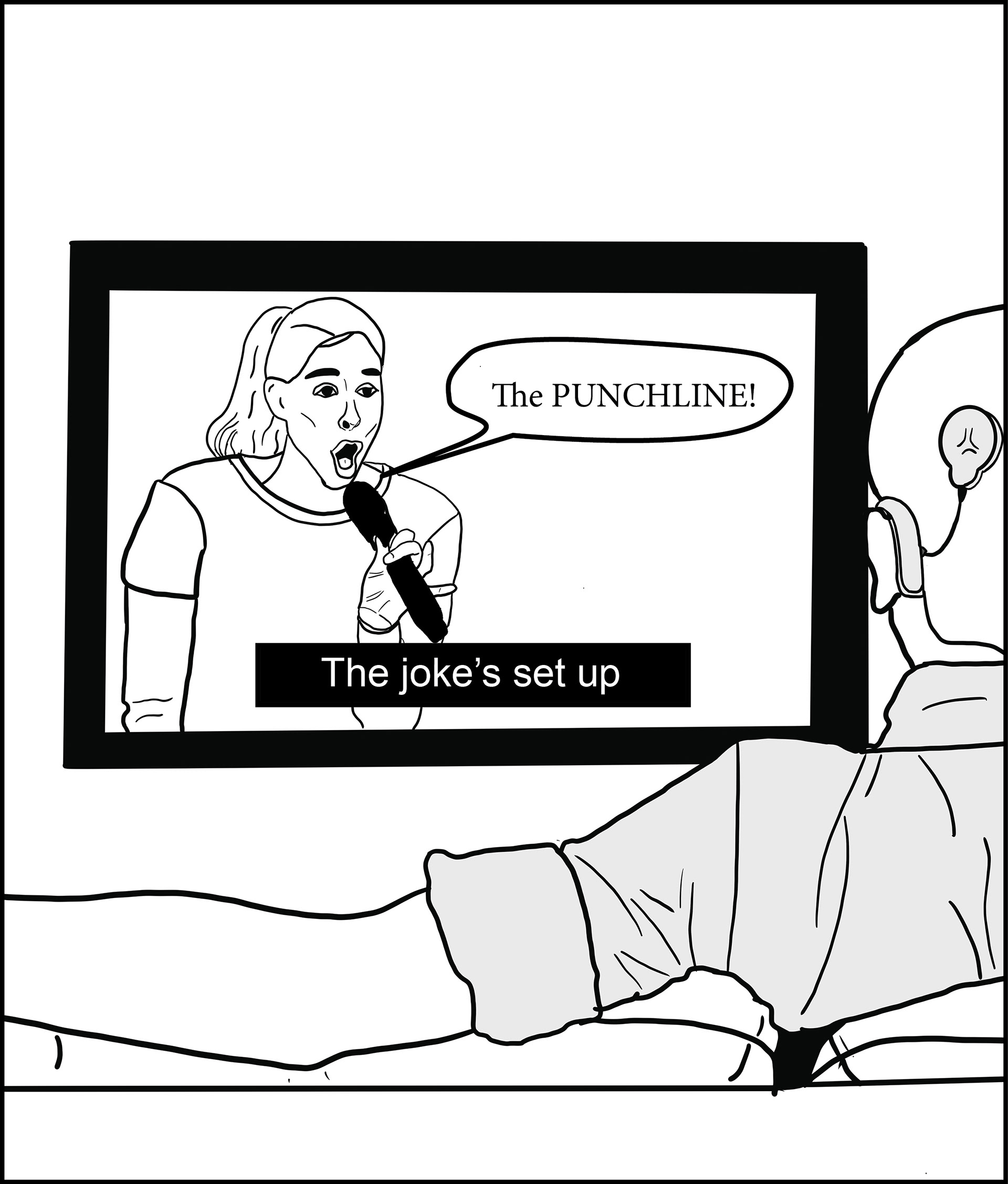
Deaf and hard of hearing individuals rely on captions to enjoy on-screen entertainment. Nearly every single program that is broadcasted by a large network contains the option of subtitles, but currently subtitles are performing the bare minimum by translating conversation and spoken word to text. For certain programs like the news or a documentary, these transcriptions convey an adequate amount of information, but for forms of entertainment like comedy, they do not.
Stand-up comedians use comic timing and intonations to elicit laughter from the audience and this is done through careful use of inflections, pacing, and pauses to emphasize certain words and often alter the meaning of what is being said. Every comic has their own unique style of speaking and the impact of a joke relies heavily on each comic’s delivery. Through current subtitling efforts by broadcasters and streaming services virtually every comedian’s delivery is homogenized when converted to text.
User Validation Experiments
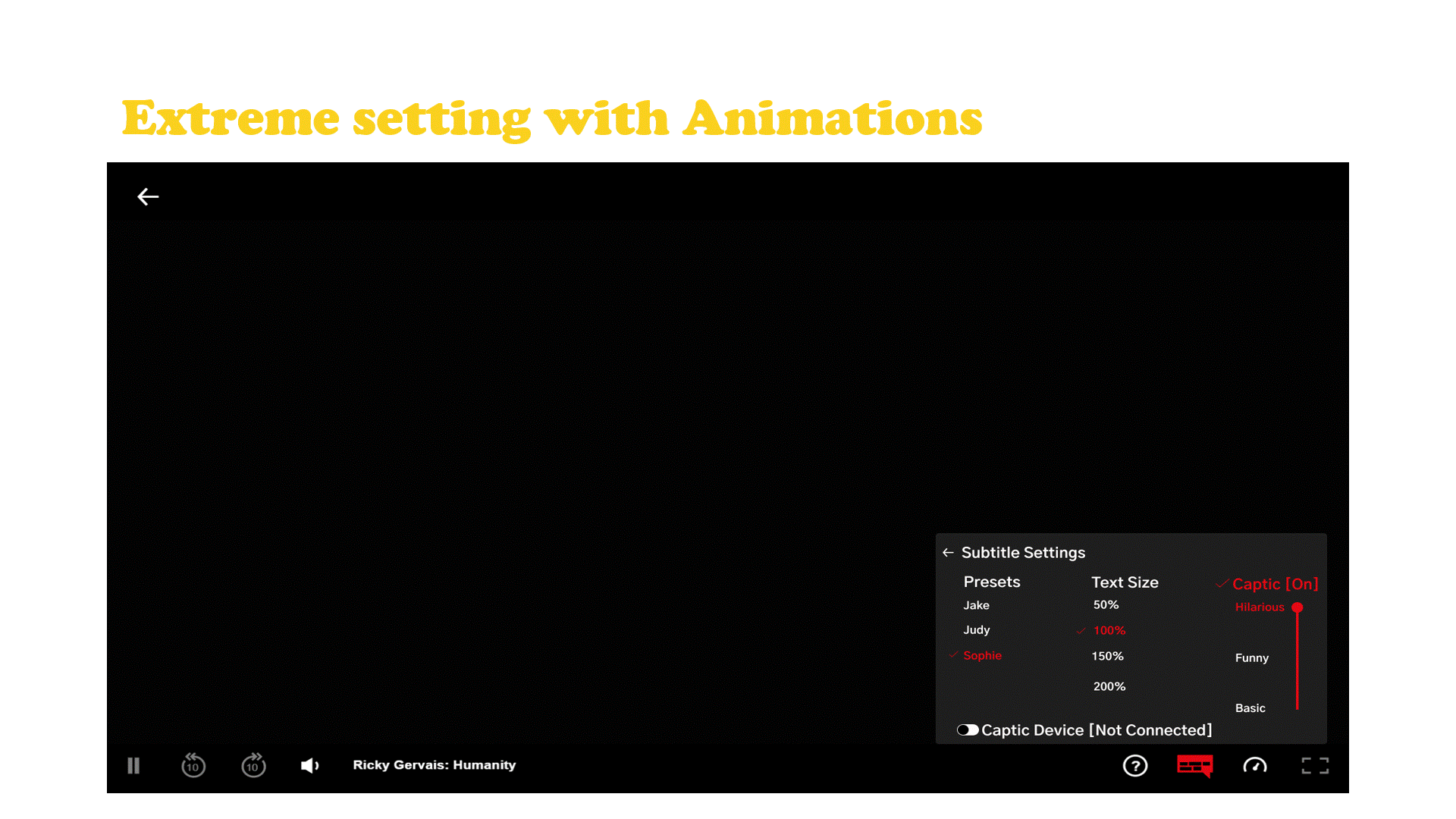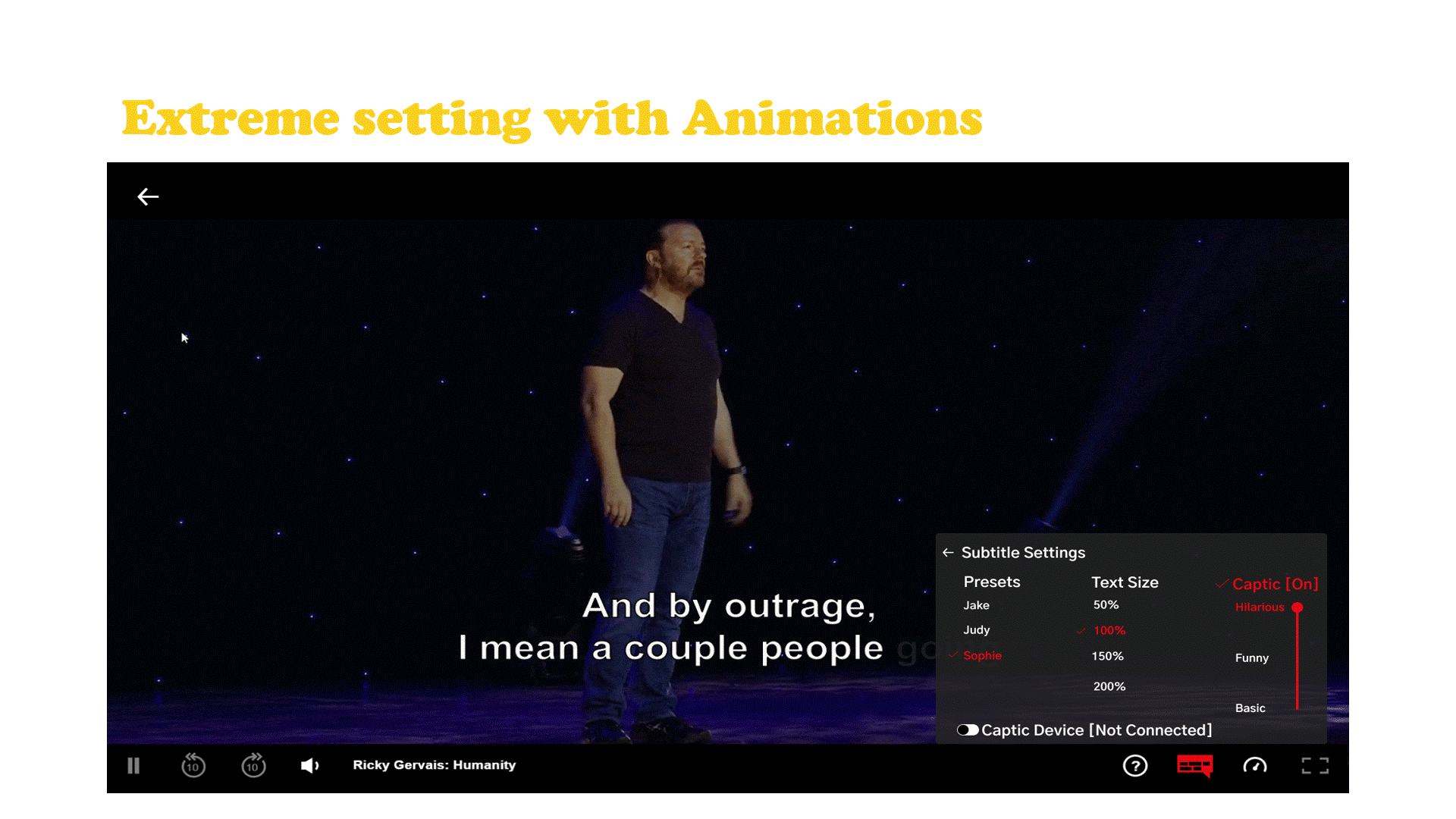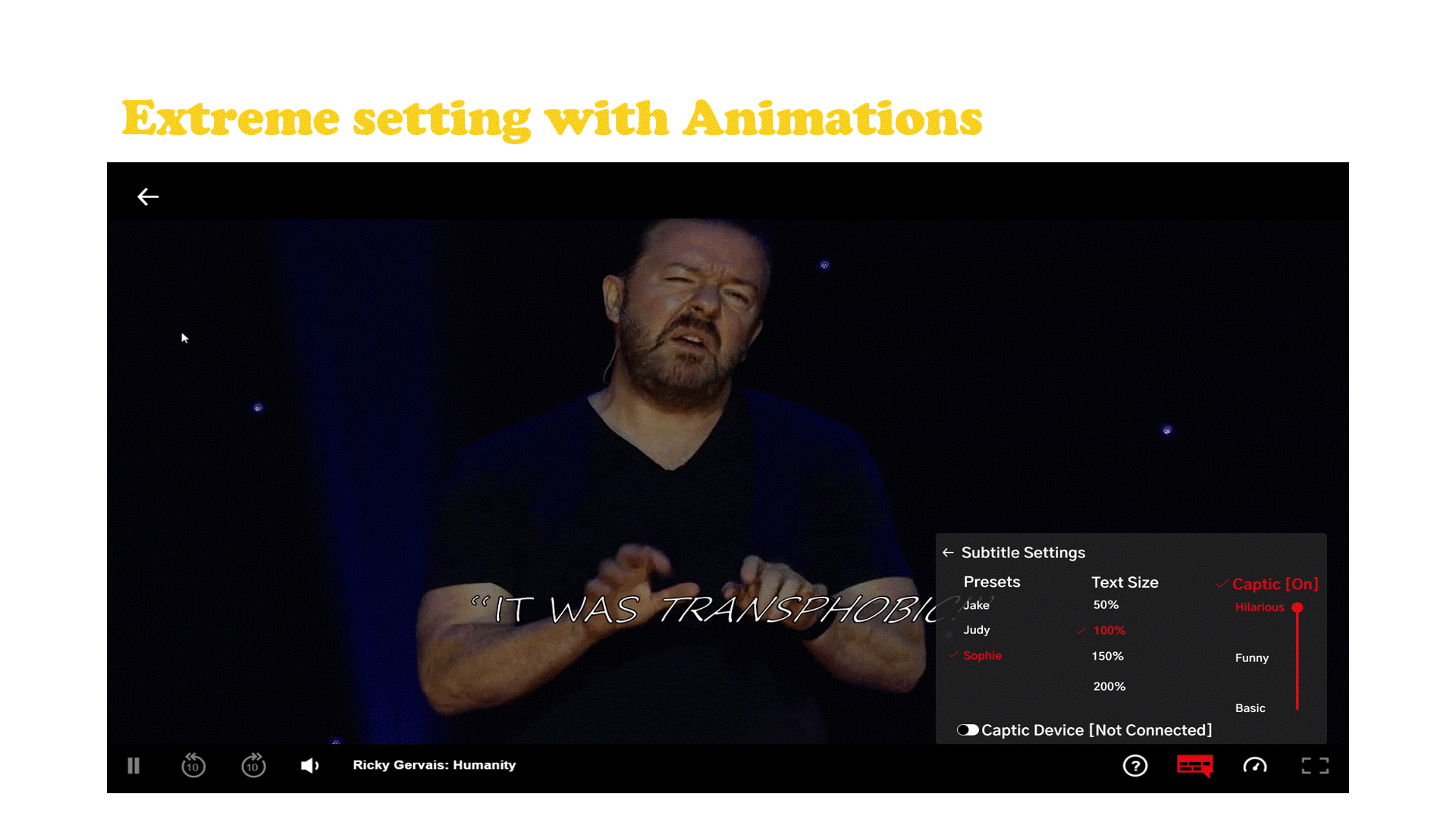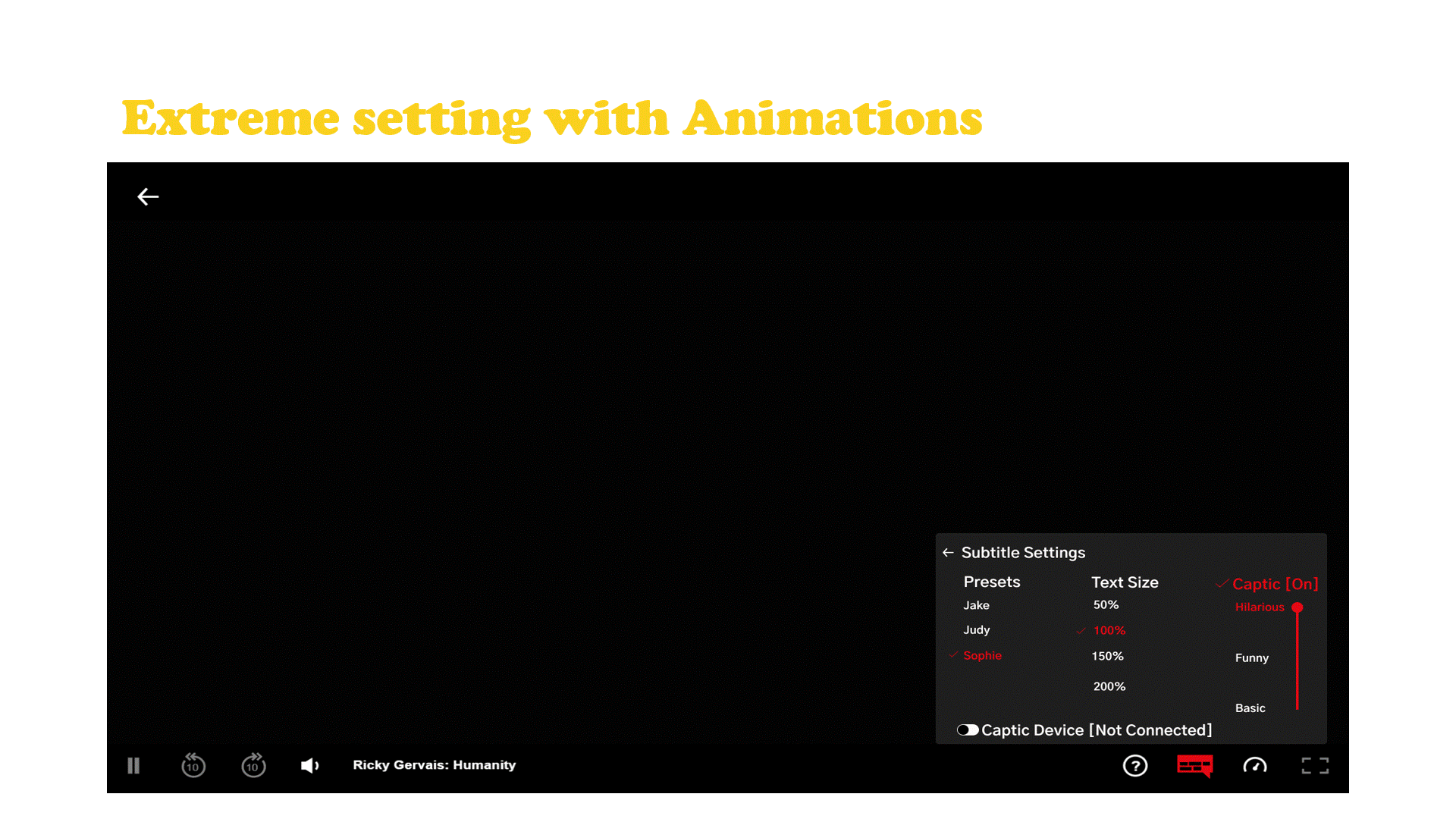
The embodiment of the experiment consisted of a muted clip from Ricky Gervais's Humanity with a haptic wearable that was programmed to vibrate when the audience was laughing.
To build the experiment I used Adobe After Effects to caption a bit from Ricky Gervais’s Humanity[13] special on Netflix. I then time-stamped every interval that the crowd laughed and went through each burst of laughter meticulously, analyzing the energy and then assigning each one a vibrational pattern. The DRV motor driver’s library consists of over 100 patterns and each pattern has the potential to communicate a different reaction from the crowd, but for this experiment I stuck with 4 patterns.
After each portion of laughter in the video was classified I used Python with OpenCV to play the video with no volume. I had a timer running and hard coded the specific intervals at which the crowd laughed. The computer was in serial communication with an Arduino which controlled the output to the motors.




“ It adds another dimension to the viewing experience” - Kat

“ It was a good experience and it enhanced the comedy” - Lior
![“Feeling [the vibrations] is more fun than just watching the titles”- Xianzhi](https://pro2-bar-s3-cdn-cf3.myportfolio.com/022b1a6e-bcfd-4d91-97e5-0cfa486f3a10/431d621d-5226-41c7-b7d9-6dc3e1c2e2ff_rw_1200.gif?h=9f294d4588c3dd6e64bedaf48a1aa4fb)
“Feeling [the vibrations] is more fun than just watching the titles”- Xianzhi

“Sometimes it makes me laugh when I don’t want to” -Mariona
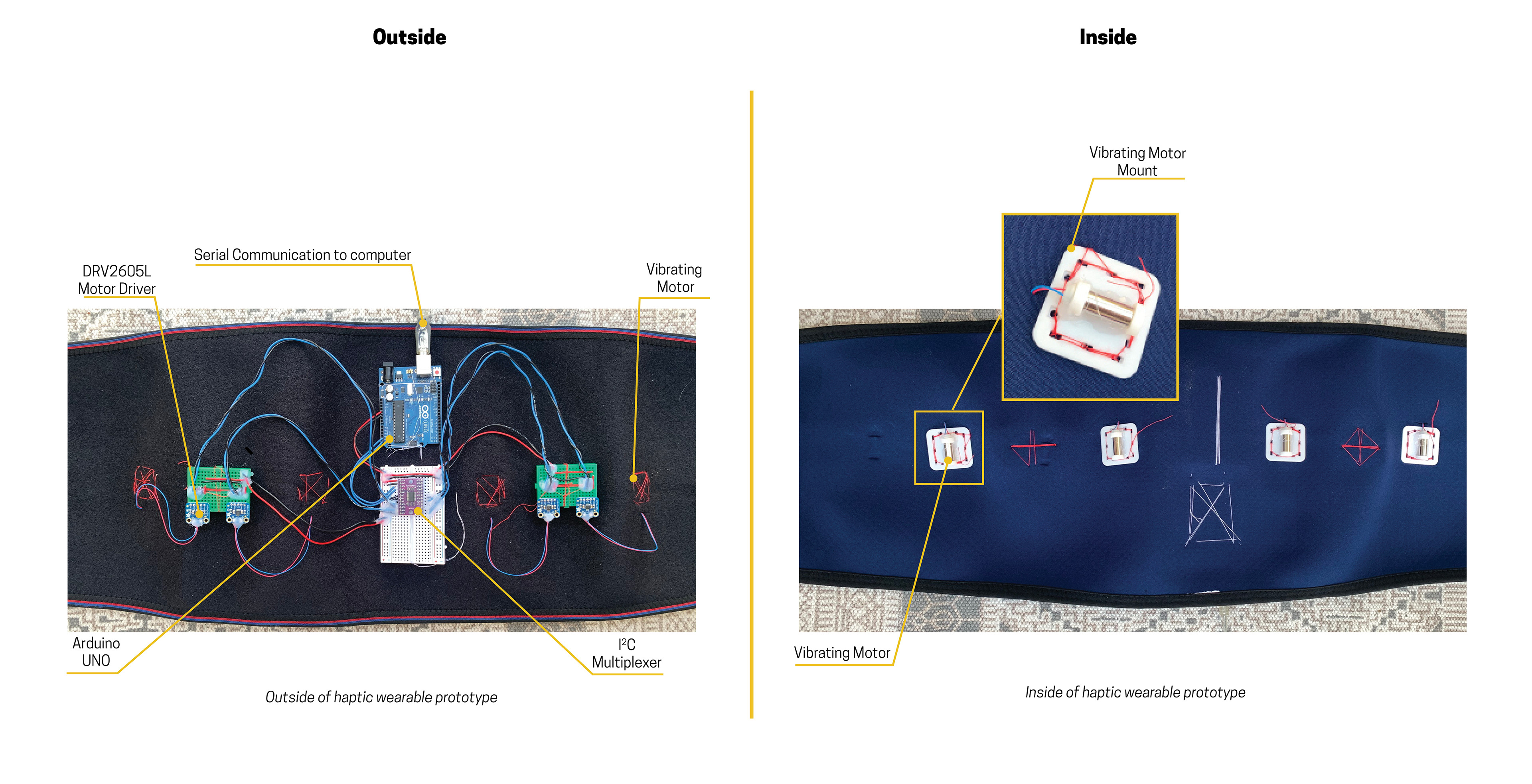
First Prototype Hardware Build
Voice Feature Classification Demonstration

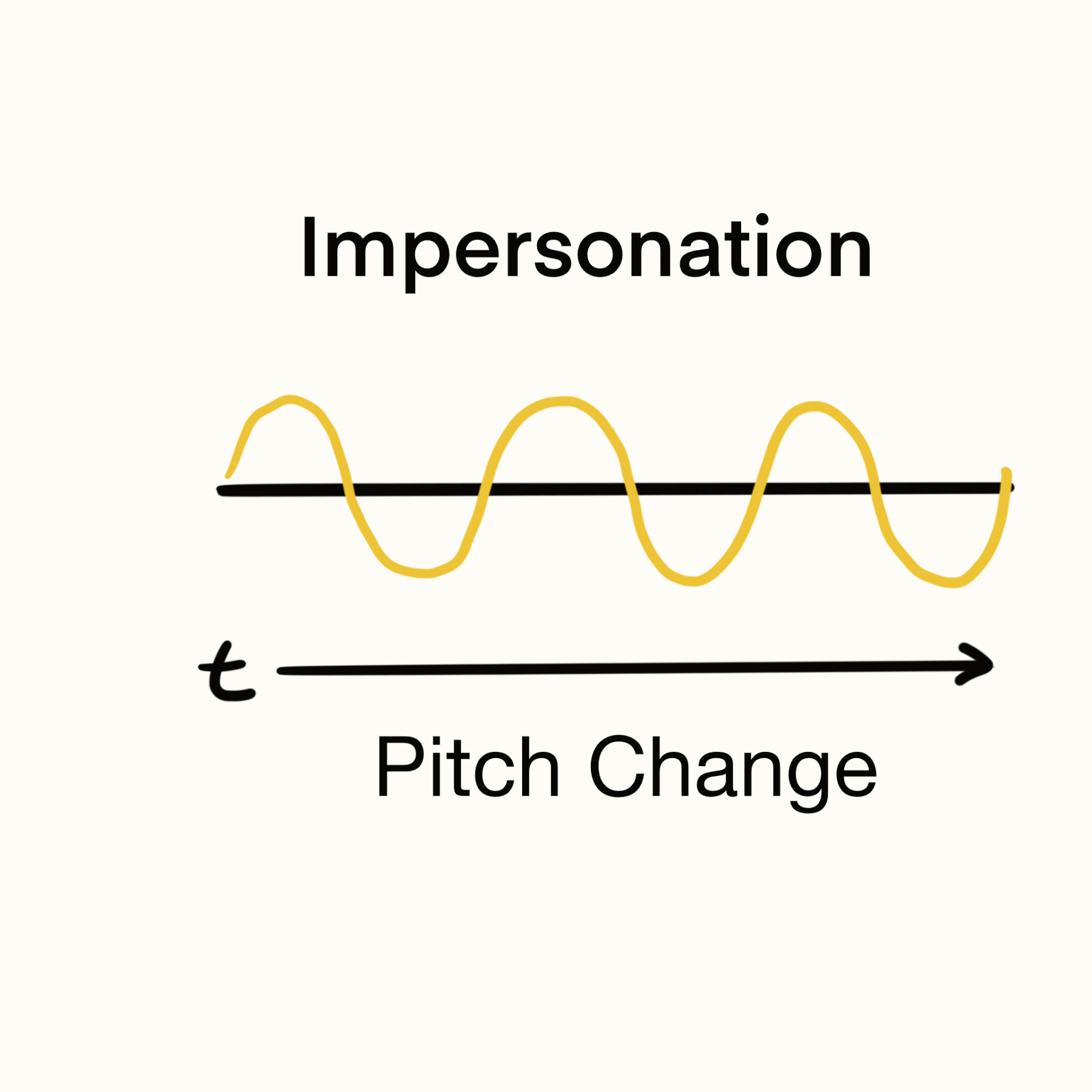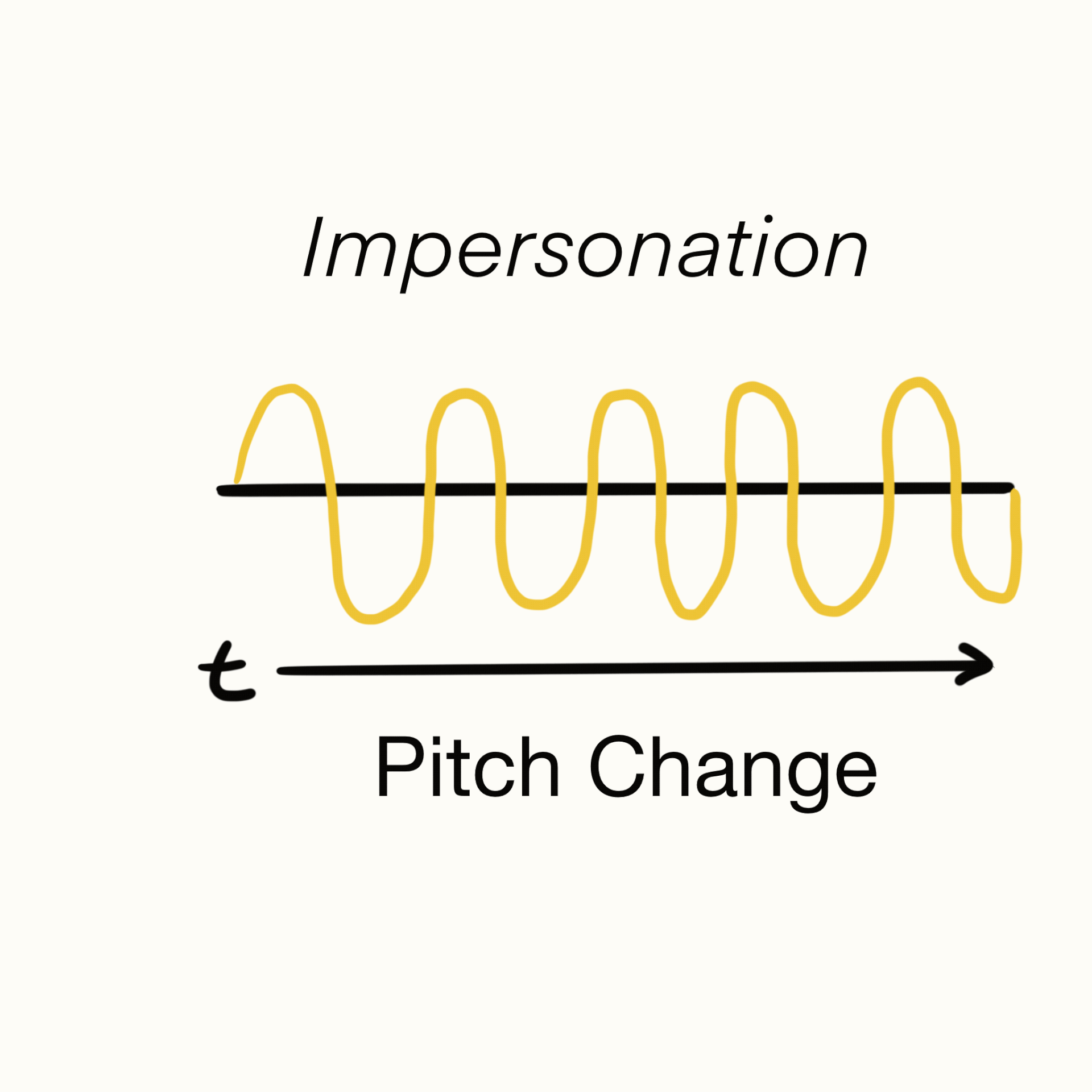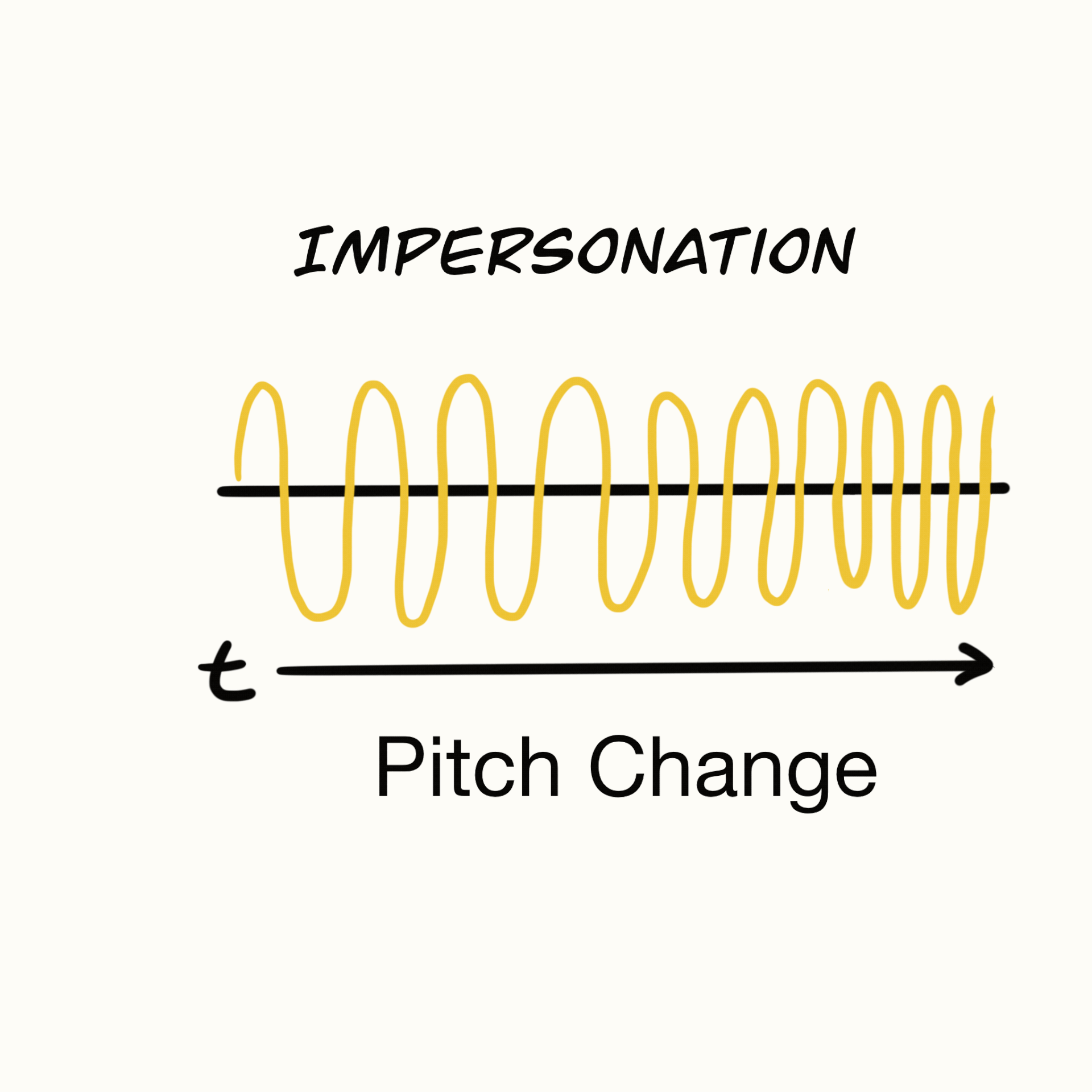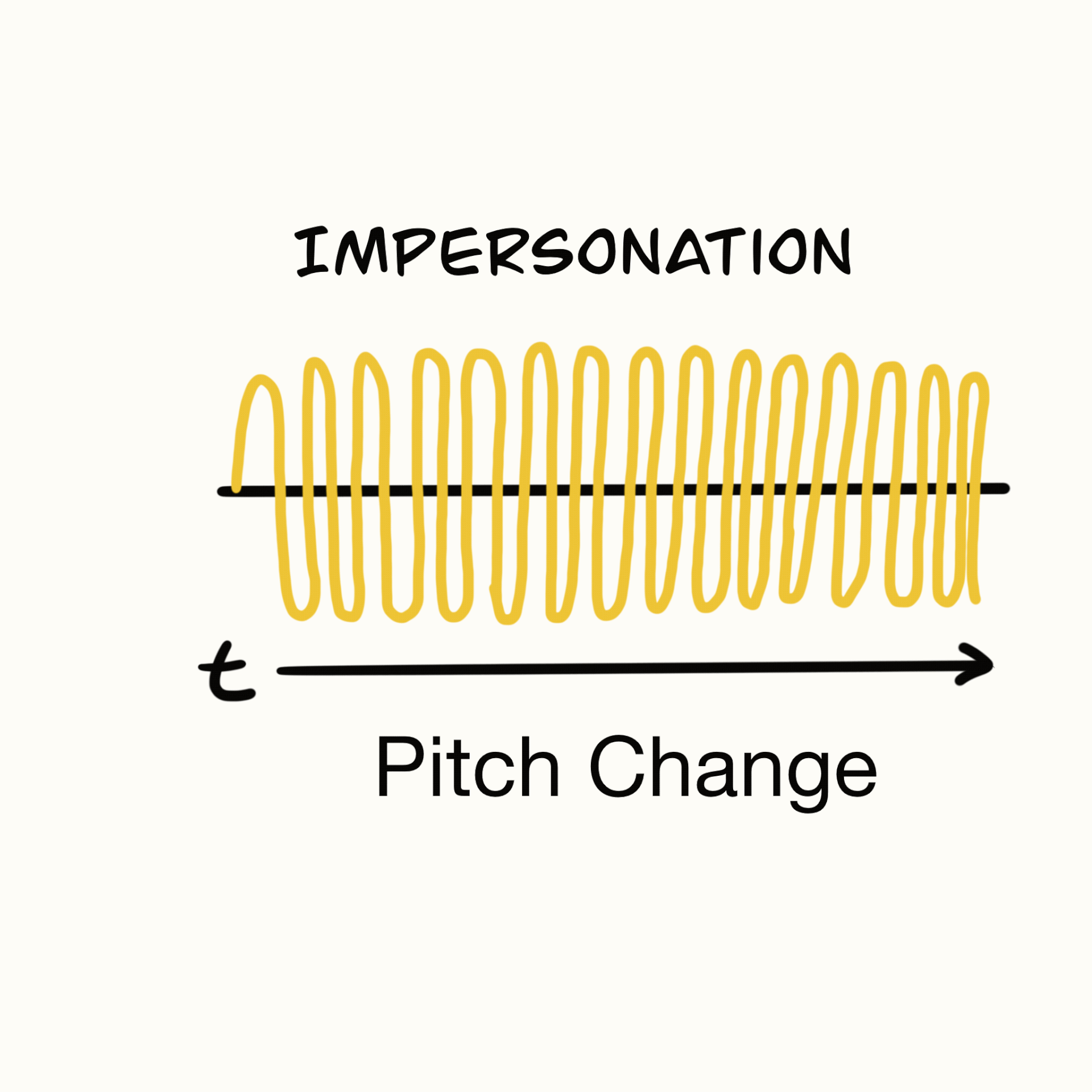





User Journey
Netflix Case Study and Final Embodiment
Netflix has established themselves as the go to platform for stand up comedy with more hours and original stand up content then any other platform and they currently don’t have any hardware of their own. The haptic wearable belt which connects to a streaming device which is hooked up to the tv that displays the captions with the user’s cell phone acting as the tv remote.




Model Factory Algorithm For Annotation of Voice Features
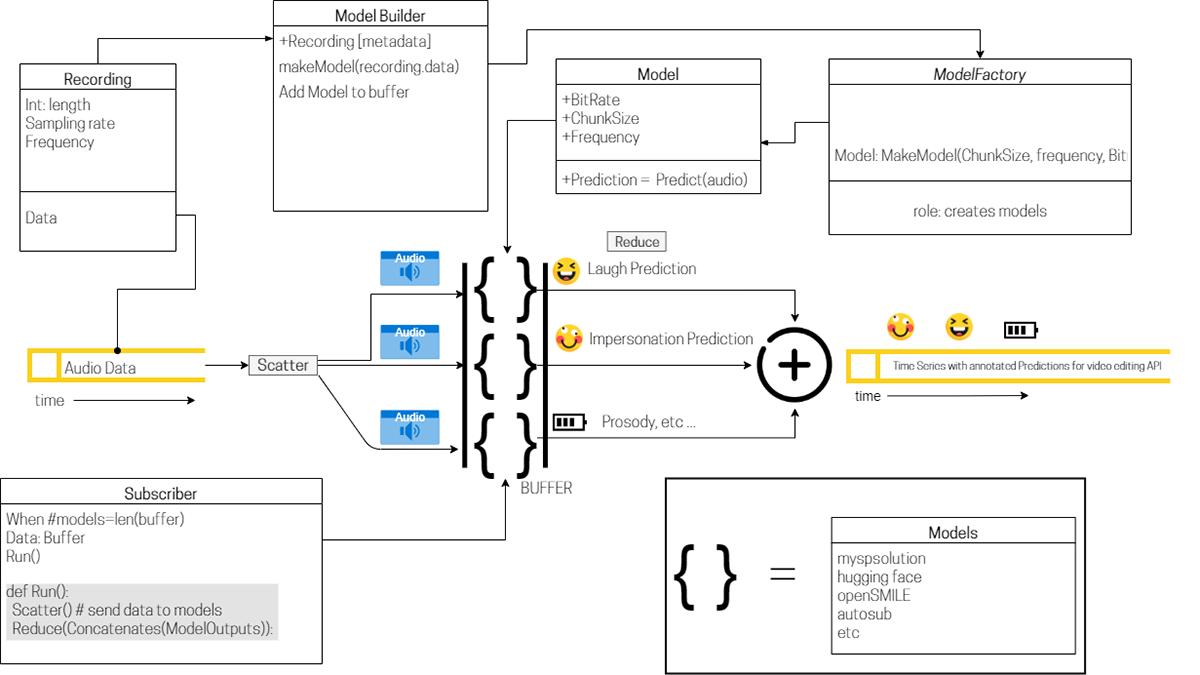
This design illustrates an autolabeling tool based on DNN models trained in a supervised fashion. The architecture of this pipeline consists of a model builder that executes a factory design pattern in order to create models and store them inside a named buffer.
The model builder constructs pretrained models geared toward inferencing using the metadata provided by the recording sample, including frequency, bit rate (expected by the model), and chunk size.
Once all models have been moved into the buffer a subscriber routes the input audio sequence to each model within the buffer in a parallel fashion using the scatter operation. Then each model runs a forward pass of its neural network to output predictions, those predictions are aggregated together in a reduce operation and added to a time series prediction buffer equal in length to the first input audio sequence. This buffer is then sent to postprocessing application plugins.
Development Journey